





DNS (Domain Name System) servers translate standard language web addresses to their actual IP addresses for network access.
DNS response time is the time it takes a Domain Name Server to receive the request for a domain name’s IP address, process it, and return the IP address to the browser or application requesting it. When it comes to DNS response times, the lower the better, and generally values less than 100ms are considered to be in the acceptable range (depending on the application).
To understand how DNS response times affect the performance of your application it is important to monitor it continually along with other metrics of application and infrastructure performance. This will help you to correlate where the problem is triggered by DNS latency and where it isn’t.
DNS response times can be optimized by (among other things) choosing the right DNS provider. There are many factors which influence the response times of a particular DNS provider, such as the geographic location of the server or how much traffic it receives. The default DNS server in use may not always be the best choice. There are many DNS options available today offering free, fast and secure DNS services.
Using Netdata you can quickly probe and compare DNS query response times across multiple DNS servers. Let’s see how to do this using the primary DNS server IPs from 5 of the most popular DNS providers.
- Google (8.8.8.8)
- Cloudflare (1.1.1.1)
- Quad9 (9.9.9.9)
- OpenDNS (208.67.222.222)
- AdGuard DNS (94.140.14.14)
As a prerequisite you need to sign up for a free Netdata cloud account and install the open source Netdata agent on the client from which you want to monitor DNS query response times. Then just go to the Netdata configuration directory (usually /etc/netdata) and run ./edit-config go.d/dns_query.conf. After entering the domains you want to use in your query and the DNS server IPs just restart netdata and the DNS query charts should be visible within seconds.
Here’s a sample configuration to monitor the query latency from the 5 DNS providers we mentioned previously.
update_every: 10
jobs:
- name: latency
record_types:
- A
- AAAA
domains:
- google.com
- github.com
- reddit.com
- netdata.cloud
servers:
- 8.8.8.8
- 9.9.9.9
- 1.1.1.1
- 208.67.222.222
- 94.140.14.14
The DNS query response time should now be visible for monitoring on your Netdata overview tab. You can see the results in the Netdata Demo Space. In this particular case you can see that most of the time the DNS response times stay within a 25ms to 75ms range but there are instances where the primary DNS from Quad9 (9.9.9.9) and AdGuard (94.140.14.14) spike significantly above 100ms.

Monitoring these values over a longer period of time, and exercising finer grain control by choosing the base protocol (UDP or TCP or TLS) that you want the DNS probing to use or selecting the DNS record types (A, AAAA, TXT, CNAME, SRV etc.) to be used as per your use-case will allow you to maximize the value you get from DNS query response monitoring.
You can modify the Group by or Filtered by chart options to drill down into the view that helps you find what you need.
You can compare how query times differ across different DNS record types, the example below shows A vs AAAA DNS query times.

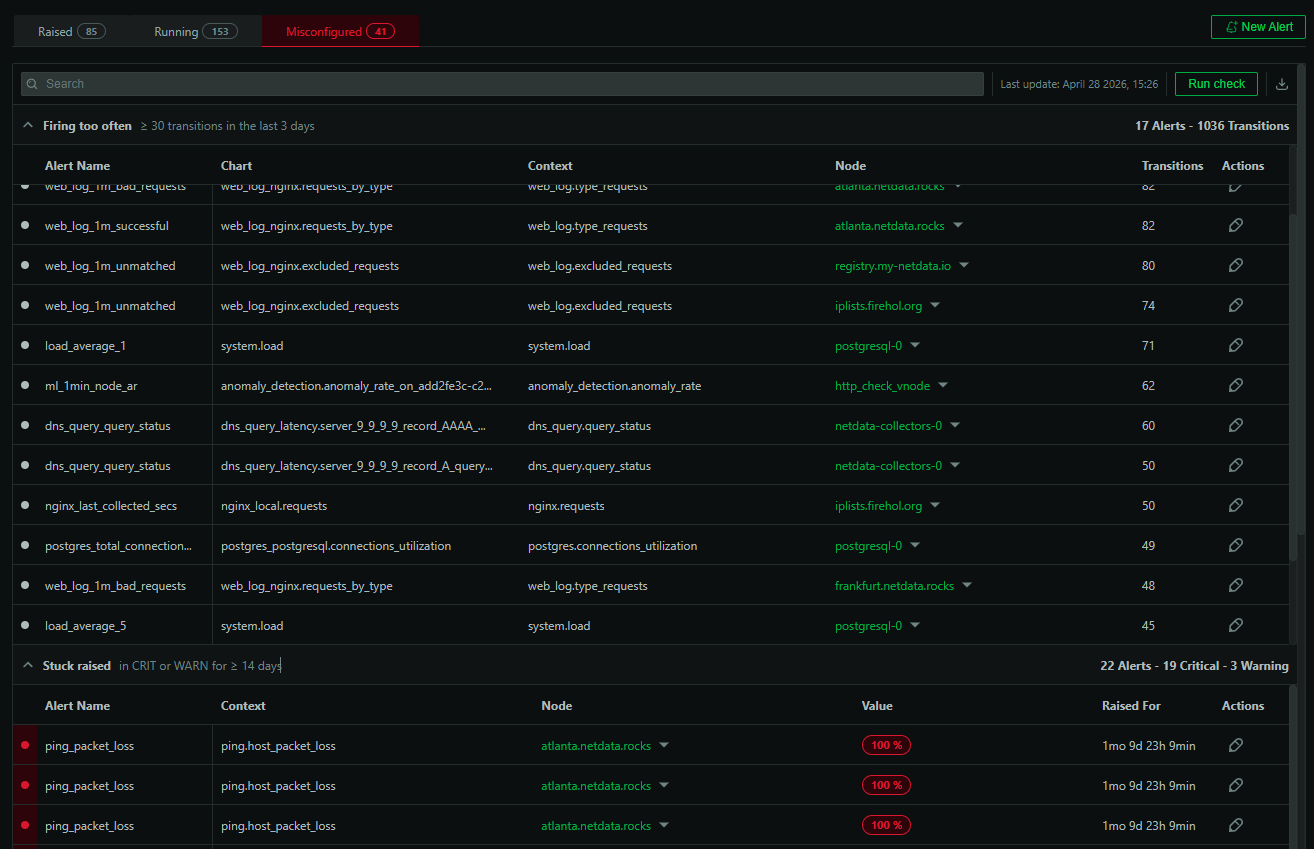
In addition to the query latency chart, there’s also a chart that gives you a quick idea if any of the DNS servers have failures. Network errors and DNS errors are called out separately.

What if you want to be notified when the DNS response times are consistently above a threshold of your choosing? Well, you can define a custom alert to do exactly this. Here’s how you would define an alert to warn you if the average DNS query round trip time over the last 10 seconds exceeds 500ms and notify you with a critical alert if it exceeds 1 second.
template: dns_query_time_query_time
on: dns_query_time.query_time
class: Latency
type: DNS
component: DNS
hosts: *
lookup: average -10s unaligned foreach *
units: ms
every: 10s
warn: $this > 500
crit: $this > 1000
delay: up 20s down 5m multiplier 1.5 max 1h
info: average DNS query round trip time over the last 10 seconds
to: sysadmin
If the conditions defined in the alert are triggered, you will be notified (for representational purposes in the below screenshot a critical alert was triggered at > 50ms)

If your monitoring use-case is different or more sophisticated such as monitoring a DNS server, the way to do this would be different. If you’re using CoreDNS, then Netdata collects and visualizes 25+ metrics that help you monitor the performance of your CoreDNS instances.
Happy Troubleshooting!