Scalability is crucial for monitoring systems as it ensures that they can accommodate growth, maintain performance, provide flexibility, optimize costs, enhance fault tolerance, and support informed decision-making, all of which are critical for effective infrastructure management.
Most monitoring solutions struggle with scalability, mainly because of:
- High data volume and velocity: Monitoring systems generate vast amounts of data and as the infrastructure grows, so does the volume and velocity of these data.
- Resource constraints: Scalability requires efficient resource utilization, leading to bottlenecks and performance issues as the monitored environment grows.
- Architectural limitations: Monitoring systems are usually designed with certain architectural constraints that limit their scalability. Most open source solutions rely on monolithic or centralized architectures that can become overwhelmed at scale.
For open source solutions scalability has always been a challenge, increasing their complexity significantly (check for example the scalability issues of Prometheus), while for commercial solutions it usually results in increased data collection to visualization latency and cost.
Netdata has been designed to excel in both vertical and horizontal scalability.
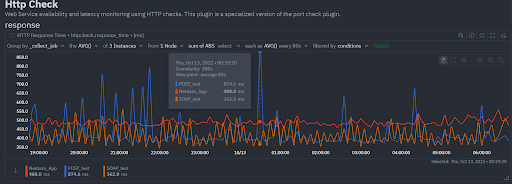
The Open-Source Netdata Agent has been designed to have extreme vertical scalability performance. Using our DBENGINE v2 we released in January 2023, Netdata is outperforming most other monitoring solutions running on the same hardware, crossing the 1 million active metrics collected with per second granularity, at 50% CPU utilization of a 16-core, 32GB RAM VM, with health and Machine Learning training and prediction enabled for all metrics.
Netdata Cloud on the other hand, has been designed to use Netdata Agents as distributed partitions of the same database, scaling horizontally without limits, outperforming most other monitoring solutions, commercial or open-source.
Netdata’s Vertical Scalability Architecture
The Open-Source Netdata is able to ingest millions of active metrics (concurrently collected metrics), with 1 second resolution, and at the same time provide an amazing query performance of several million points per second.

To achieve this level of scalability, Netdata uses sophisticated mechanisms that allow it to make the best use of the system resources available:
NIDL framework
Netdata’s data collection protocol uses the NIDL (Nodes, Instances, Dimensions, Labels) framework, minimizing overhead for processing vast amounts of metrics with extensive metadata. Metrics values are associated with Dimensions. Dimensions belong to Instances. Instances have labels. Instances belong to Nodes. Nodes have more labels.
With the NIDL framework, data collection happens in 2 phases: definition of Nodes, Instances, Dimensions and Labels is executed independently of ingesting data collection samples for them, allowing ingestion of collected metrics to run at full speed, without the need for processing metadata on every sample.
Data collection efficiency
Netdata’s database engine uses paging for each metric. So, each metric collected has a page in memory where collected samples are appended. When that page becomes full, it is added to an extent together with pages of other metrics, which is then compressed and stored to disk.
To improve query performance, metrics of the chart share a correlation id, which is used during extent construction to select per extent metric of the same chart.
When collecting millions of metrics per second, it is crucial the “page full” events of all those metrics not to happen concurrently. If they do, the congestion point will be memory allocation. To solve this, when a metric is first collected, Netdata is using a hashing algorithm to provide a smaller first page, so that the anniversaries of “page full” events (and therefore the rate of disk commits) are spread across time evenly.
The full pages that have been committed to disk are of two kinds: either they have a size that could be reusable for another metric, or they are some custom size that was required to control the anniversary of the metric. The reusable ones are managed by a special array allocator with a single thread performance 4x the glibc one, but which also achieves 2x its single thread performance when multi-threaded. Of course this uses more memory, but it is a tradeoff of some temporary memory for a lot faster allocations.
With this setup, Netdata can run amazingly fast while ingesting metrics.
Database storage
Committing metrics to disk is handled by independent workers that do not interfere with data collection. So, while data collection is filling up the next pages, other threads are aggregating full pages into extents, compressing them and saving them to disk.
Similarly, at query time Netdata uses a prioritized pipeline to satisfy loading, uncompressing and caching of each metric page. While the query engine executes the query on one metrics, the other metrics required for the same query are loaded from disk using independent workers, in parallel.
Database rotation
Database rotation is handled automatically by the disk workers and is totally independent and transparent to data collection. To simplify database rotation, Netdata creates new data files and when the total capacity of them on disk reaches a certain point, a new data file is added while the oldest data file is removed.
The same workers are also responsible for updating the metrics registry for the retention available for each metric, synchronizing the metadata required for data queries.
Database tiering
Netdata can maintain a very long retention of the collected data, with its ability to aggregate collected points. Unlike other solutions that downsample data, Netdata aggregates the collected points. So, although it loses the ability to provide a time-series for the aggregated points, it still maintains the minimum value, the maximum value, the average value, the number of points aggregated and the number of points that were anomalous.
Database tiers are different database instances. The data collection mechanism automatically maintains up to 5 aggregations of all samples collected, each aggregation associated with a different database instance, following its own paging, saving, and rotation mechanisms.
Sophisticated caching
Each Netdata agent includes a sophisticated query engine, capable of querying at scale, dozens of millions of points per second. To achieve this scalability, Netdata uses several indexes for the metadata and 3 levels of caches for metric data.
For caching, Netdata uses 3 distincts caches: The main page cache which stores the pages currently being collected and pages recently used. The open data file page cache which stores metadata for the pages committed to the currently open data files. The extent cache which stores compressed extents loaded from disk. This chorus of caches is designed in a way to optimize speed and efficiency even on slow disks, allowing Netdata to achieve extreme cache efficiency and query performance, even on rare or unusual use cases.
Netdata’s Horizontal Scalability Architecture
Netdata has been designed to scale horizontally infinitely.

High performance streaming and metrics replication
Each Open-Source Netdata Agent is able to act as a data collection agent for the node it runs on, but also as a “parent” for other Netdata agents, ingesting in real-time their metrics and maintaining a retention for them.
Using streaming, engineers can create multiple metrics centralization points within their infrastructure, aggregating metrics from nearby nodes and offloading production systems.
This feature is used for:
-
Offloading production systems
Netdata Agents installed on production systems can be configured to push their metrics to a nearby centralization point, delegating ML, alerting and retention to them, to free system resources and minimize the impact of monitoring on sensitive production applications.
-
Ephemeral nodes
Ephemeral nodes can be configured to push their metrics to a nearby centralization point, so that their data will be available even after these nodes are not needed anymore.
-
High-availability, clustering and failover
Replicating metric data and maintaining copies of them, improves the availability of data in case of failures. This replication can be across data centers and cloud providers.
Netdata allows the configuration of active-active parent clusters, so that all parents in the cluster will have all the data of all nodes and any Netdata Agent pushing metrics to them can use any of the parents to send its metrics.
Distributed data collection
When using centralization points, each data collecting Netdata Agent is pre-processing and normalizing collected data, parsing metadata and labels, and interpolating collected values so that everything is ready for storage.
Centralization points (the Netdata Parents) are receiving metrics ready to be stored to their database. This process allows Netdata Parents to ingest several millions of points per second, using the minimum of system resources.
Distributed querying
Although the query performance of each Netdata Agent is exceptional, Netdata further improves its query scalability with its ability to query in parallel multiple agents and merge their results for each chart to be presented on a dashboard.
When Netdata Cloud receives a data query request, it first goes through a routing decision. This routing decision distributes the request to multiple Netdata Agents, each of which is executing the part of the query it has data for. Netdata Cloud then receives all the responses back, merges the results into a single response which it sends back to the dashboard for visualization.
This process is transparent for the users and automatic. Netdata Cloud is able to split a multi-node chart query of a huge infrastructure into hundreds of pieces, provided that there are enough agents and centralization points (parents) to execute them in parallel.
To minimize the bandwidth required between Netdata Agents and Netdata Cloud, the query routing decision takes into account the availability of centralization points (parents) that can provide responses for multiple Netdata Agents at once. The query engine of Netdata is replicated among Netdata Agents and Cloud (both can perform the whole of it) and the system is able to execute different aggregations at different levels depending on data availability, to minimize data transfers.
Using this process Netdata can scale horizontally infinitely, while maintaining very fast, low latency queries.
Time for a truly scalable monitoring solution
The challenges of scalability in monitoring systems cannot be overstated. As modern infrastructures continue to evolve and grow in complexity, the need for scalable monitoring solutions becomes increasingly critical. A truly scalable monitoring system must be able to handle high data volume and velocity, optimize resource utilization, overcome architectural limitations, efficiently store and retrieve time-series data, support horizontal scaling, and accommodate distributed querying.
Netdata has been specifically designed to address these scalability challenges. With exceptional vertical and horizontal scalability, Netdata offers a robust and efficient monitoring solution that outperforms most other commercial and open-source alternatives. By leveraging the strengths of the Netdata Agent and Netdata Cloud, organizations can enjoy a seamless, powerful, and scalable monitoring experience that keeps pace with their ever-growing infrastructure.
Happy Monitoring!