



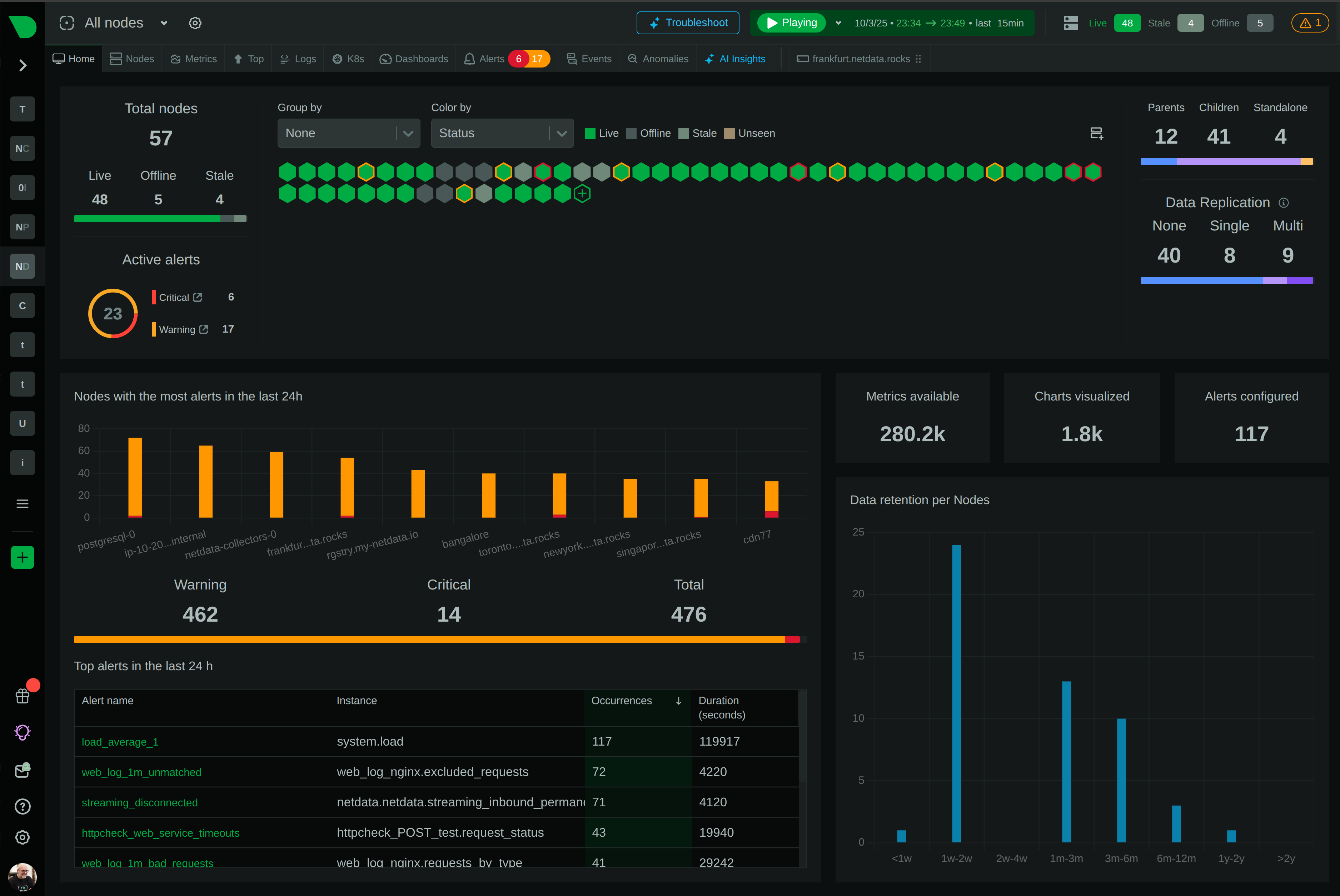


We often hear the term load used to describe the state of a server or a device, but we’re here to tell you what it means, precisely, and how to monitor it.
What is server load?
We often hear the term “load” used to describe the state of a server or a device. But what does it really mean?
System load is a measure of the amount of computational work that a system performs. An overloaded system, by definition, isn’t able to complete all its tasks per schedule - this affects the performance and productivity of the system. And while “load” often gets conflated with CPU usage there’s a lot more to it.
Technically the term “load” refers to the number of processes waiting in queue to be processed and “load average” is represented as three separate averages over the previous 1 minute, 5 minutes and 15 minutes. The lower the load the better your server performance. Several factors can lead to high “load” - the usual culprits are CPU consumption, disk I/O and memory (more specifically swapping triggered by low available memory).
How to check the current server load?
If you are using Linux (or other Unix based OS) you can check what the server load is by executing the “w” command (or the “uptime” command) which generates output in the following format:
11:37:09 up 1:07, 0 users, load average: 0.29, 0.17, 0.11
We’re interested in the last entry, which gives the three load averages over the previous 1 minute, 5 minutes, and 15 minutes. Load averages can change and fluctuate significantly which is why the three load averages is useful.
The load average numbers should be interpreted as percentages, considering the number of cores in the system.
For example, in the above example the 1 minute load average is 0.29 - if this was a single core system then this equates to a 1 minute load average of 29%. If however this was a quad core system then this would equate to a 1 minute load average of only 7.25% (29/4). How do you check which application is causing load?
OK - so now you know if your system is loaded and what the load averages are. But what is causing the high load? Which application or process is the culprit?
htop is a great command (available by default on many Linux distros) to check which application(s) or process(es) could be causing high load.
The output of this command looks something like this and gives you a quick idea of the CPU and Memory consumed by each process.

To understand disk io usage per process, you can use the following command
pidstat -dl
Linux 5.15.68.1-microsoft-standard-WSL2 (SHM-PC) 10/18/22 _x86_64_ (8 CPU)
12:12:54 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
12:12:54 112 213 0.02 0.00 0.00 0 /usr/sbin/netdata --special-spawn-server
12:12:54 112 464 0.13 0.00 0.00 0 bash /usr/libexec/netdata/plugins.d/tc-qos-helper.sh 1
- kB_rd/s: Number of kilobytes the task has caused to be read from disk per second.
- kB_wr/s: Number of kilobytes the task has caused, or shall cause to be written to disk per second.
- kB_ccwr/s: Number of kilobytes whose writing to disk has been canceled by the task. This may occur when the task truncates some dirty pagecache. In this case, some IO which another task has been accounted for will not be happening.
How to monitor your server load?
Checking the value of a metric and monitoring that metric are two completely different things.
While the commands we talked about are very useful they are not built for 24x7 monitoring or for going back in time to the root cause of an issue.
To comprehensively monitor system load and all the details on which applications could be causing this load you need to use a monitoring solution like Netdata that allows you to constantly monitor the load, configure alerts if the load exceeds a certain threshold, go back in time to analyze time periods of interest and much more. Netdata automatically monitors server load so no extra configuration is needed.
The load chart shown below is present in the System Overview section and shows the three load averages as a timeseries.

If the load averages exceed pre-thresholds then automated alerts are triggered - you can of course modify the thresholds per your use-case.

The applications section contains charts for CPU, Disk, Memory and much more at process group level so you know what could be causing the load at the time period you are interested in

Real world load test
Now for some fun. Let’s create some load and figure out which application caused it.
Here’s the load creator bash script that we’ll be using to trigger different types of loads periodically.
And we’ll use Netdata to:
- Detect if the load is high
- Measure the load averages
- Investigate which application is causing the load
Netdata automatically detects hundreds of custom applications automatically, and you can add your own app so that the name of your application shows up in the charts
and doesn’t get clubbed under “other”. The way to do this is by editing the /etc/netdata/apps_groups.conf and adding the following line.
LoadCreator: load_creator.sh
The first field is the name that shows up on the chart in the Netdata UI, the second field is the name of the script (wildcards work too in case you want to club multiple processes under one application name).
Here’s a quick video walkthrough of how to use Netdata for load monitoring and identifying which application is causing load.
To see this in action in an interactive environment, check out the Netdata Demo Space.
Let us hear from you
If you haven’t already, sign up now for a free Netdata account!!
We’d love to hear from you – if you have any questions, complaints, or feedback, reach out to us on Discord or Github.. Happy Troubleshooting!