Unlocking the full potential of monitoring through ML integration, anomaly detection, and innovative scoring engines.
Machine Learning has been making waves in various industries, but its adoption in the monitoring and observability space has been slower than expected. Many “ML” features remain gimmicky and do not provide actual real world value to users that encourages their further use.
At Netdata, we firmly believe that ML is crucial for monitoring, and we’ve taken an ML-first approach to provide users with powerful tools and insights. In this blog post, we’ll discuss the reasons behind our belief in ML, how we’ve integrated ML into our charts and visualizations, our query engines, the scoring engine we’ve built, and how these innovations enable metrics correlations and anomaly advisor.
Why ML is Crucial for Monitoring
The current state of monitoring largely consists of agents that primarily gather and transmit data, with minimal to no processing performed on the collected metrics. This methodology often results in a deluge of information, making it increasingly challenging for users to pinpoint the root cause of issues and effectively address them. Incorporating Machine Learning (ML) into monitoring solutions can transform this landscape by unlocking the potential of collected data to deliver more meaningful, insightful, and actionable information.
When used correctly ML has the potential to improve the accuracy and efficiency of alerting mechanisms by reducing false positives and negatives, which often plague traditional monitoring systems. This can empower users to focus on addressing genuine issues, ultimately leading to reduced Mean Time to Resolution (MTTR) and enhanced system stability.
Seamlessly integrating Machine Learning capability into observability solutions is essential for harnessing the full power and potential of the underlying data.
Integrating ML into Charts and Visualizations
Netdata’s anomaly detection works by analyzing raw metrics data and identifying patterns that deviate from the norm. This information is then directly integrated with all our charts and visualizations. So at practically any point in your troubleshooting journey you always know whether what you are seeing is anomalous or normal.
This fusion of raw metrics and ML-based anomaly information simplifies the troubleshooting process and aids in faster decision-making. By eliminating the need for manual identification of anomalous behavior, users can now focus on addressing the underlying issues, ultimately reducing the time and effort required to maintain optimal system performance.
Every Netdata chart now comes with the following visualizations, intended to surface the knowledge about whether something is normal or abnormal at any given point in time:
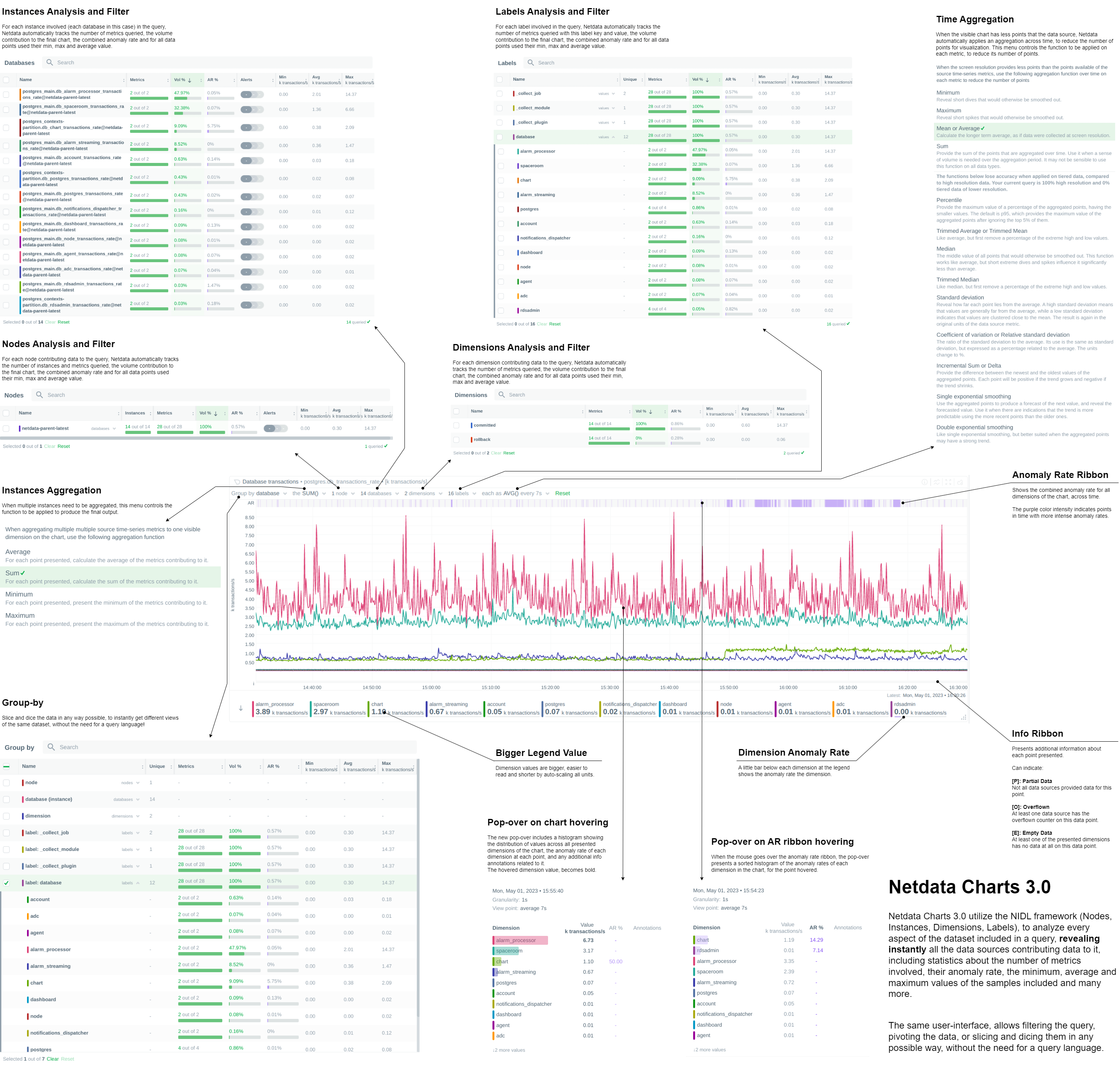
Anomaly Rate Ribbon
Above every chart, you can see the anomaly rate ribbon, the intensity of color indicates how anomalous the metrics on the chart were at any given instant in time.
Anomaly Rate per Dimension
The dimensions legend at the bottom of each chart also contains a horizontal indicator of how anomalous each dimension that contributed to this chart was at any given point in time.
Anomaly Rate % in all table tooltips
And every tooltip table that pops up when you hover or select different parts of the composite chart also presents the drilled down anomaly rate (AR) percentages
For a full breakdown of all the information you can get from each chart, click and zoom into this helpful infographic.
Highly Efficient On-Device Unsupervised ML
Incorporating machine learning (ML) capabilities into any system can prove to be a double-edged sword, as it often introduces additional overhead and complexity that may hinder overall performance. And user’s are often left having to choose between better accuracy and functionality and optimized performance.
At Netdata, we understand this concern and it has been a core design principle for us to incorporate ML capabilities without sacrificing accuracy or system efficiency. To achieve this, we have designed our query engines to effectively return anomaly information while minimizing additional overhead.
Our approach leverages the implementation of highly optimized ML algorithms that execute directly on the Netdata Agent, eliminating the need for resource-intensive external processing. By running these algorithms locally on your device, we ensure that users can access valuable insights and detect anomalies in real-time, without compromising system performance or stability.
For more details on how Netdata’s machine learning actually works, check out this video.
## The Scoring Engine and Metrics CorrelationsSo we have the raw metric data and anomaly rate for each metric and dimension available at a per second granularity - and possess an efficient mechanism to query this. But is this enough to reduce the cognitive burden on somebody who needs to get the most relevant information in the heat of troubleshooting?
We didn’t think so - so the next step was to build a scoring engine that assigns weights to metrics based on their relevance and importance. This scoring engine, accessible through the weights endpoint, enables metrics correlations and anomaly advisor, two powerful features that help users better understand the relationships between metrics and identify potential issues.
The scoring engine takes into consideration factors such as historical data, trends, and user-defined preferences to calculate the weights for each metric. This targeted approach ultimately leads to improved overall monitoring efficiency, as users can now focus on the most relevant metrics for their specific use cases.
For more information and some useful tips on how Metrics Correlation can aid with your troubleshooting, please read the documentation.
Anomaly Advisor: A Smarter Way to Troubleshoot
Netdata’s Anomaly Advisor leverages the power of the scoring engine and uses the assigned weights to identify the most relevant anomalies, providing users with a prioritized list of potential issues. The Anomalies tab quickly lets you find periods of time with elevated anomaly rates across all your nodes. Once you highlight a period of interest, Netdata will return a ranked list of the most anomalous metrics across all selected nodes in the highlighted timeframe.
This approach not only reduces the noise in monitoring but also helps users quickly identify and address the most critical issues, resulting in a more proactive and efficient monitoring process.
Here is a video walkthrough of Anomaly Advisor by Andy (Netdata’s ML lead) to get you started.
At Netdata we are committed to pushing the boundaries of what’s possible in monitoring.
Visit our demo space to explore our ML-powered features and if you like what you see, you can sign up for free.