






MySQL Monitoring
What Is MySQL?
MySQL is a widely-used open-source relational database management system. It is a crucial component in web application architecture and is known for its reliability, scalability, and performance. MySQL supports a variety of database-driven applications by enabling efficient storage, retrieval, and management of data.
Monitoring MySQL With Netdata
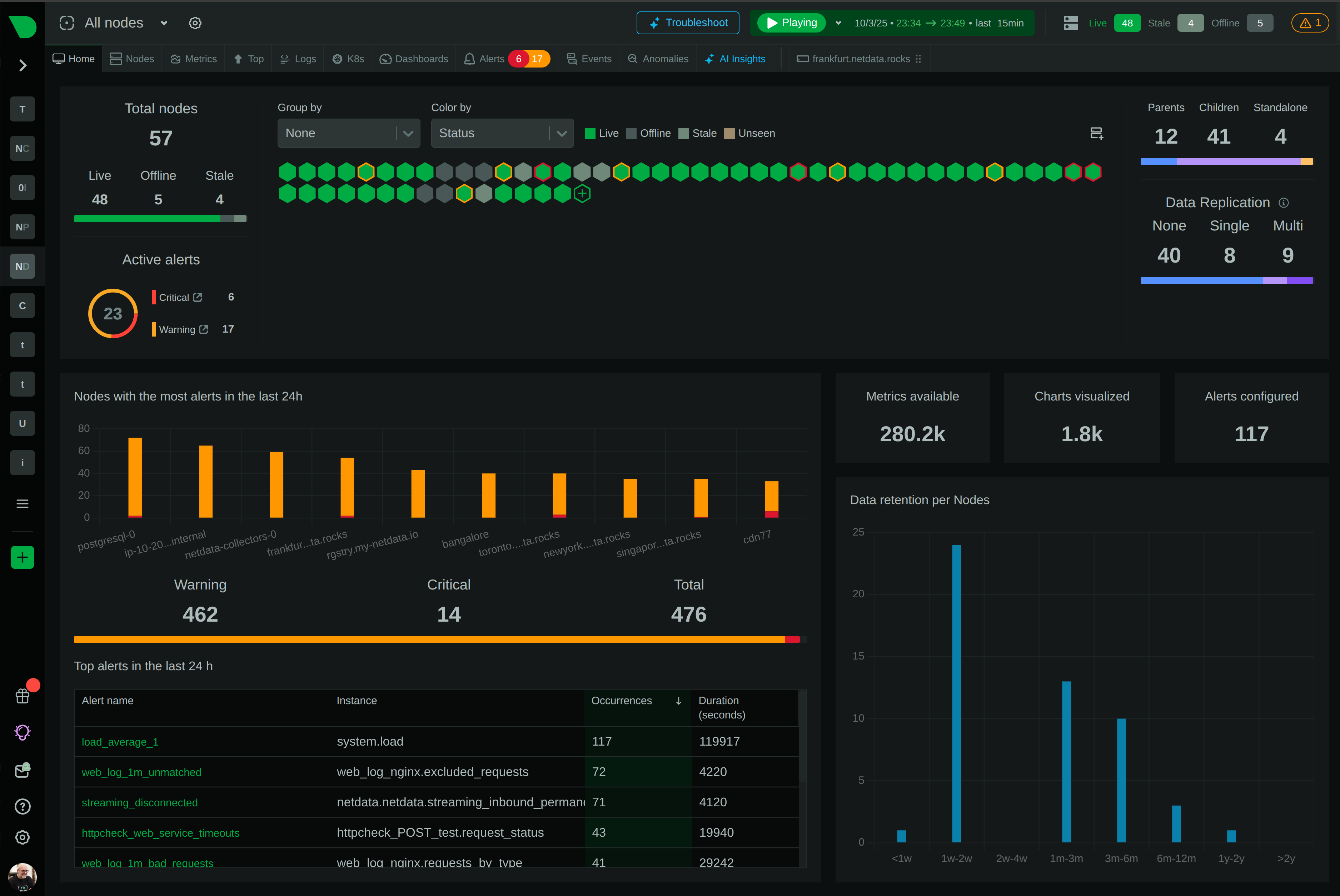
Netdata offers real-time, insightful metrics and monitoring capabilities required for effective MySQL monitoring. With Netdata, you gain access to detailed visualizations and alerts to ensure that your MySQL server operates optimally. This is achieved via Netdata’s MySQL monitoring tool which seamlessly integrates and enables deep analytics of your MySQL instances.
Why Is MySQL Monitoring Important?
Monitoring MySQL is critical for identifying performance bottlenecks, ensuring uptime, and maintaining the overall health of your database systems. By keeping an eye on key metrics, such as query performance and replication status, and utilizing tools for monitoring MySQL like Netdata, you can preemptively address potential issues before they escalate.
What Are The Benefits Of Using MySQL Monitoring Tools?
Utilizing MySQL monitoring tools provides numerous benefits:
- Proactive Issue Detection: Quickly identify and address performance issues before they impact end-users.
- Comprehensive Insights: Access detailed metrics to understand resource usage and application behavior.
- Enhanced Performance Tuning: Optimize queries and server configurations based on data-driven insights.
- Improved Resource Management: Foresee and manage capacity requirements efficiently.
Understanding MySQL Performance Metrics
To effectively monitor MySQL, it’s important to understand the performance metrics Netdata provides:
MySQL Network Bandwidth
Measures the network input/output of the MySQL database.
Queries Per Second
Shows the volume of queries handled by the server.
Connection Errors
Counts errors in connection attempts, useful for diagnosing network issues.
| Metric Name | Description |
|---|---|
mysql.net | Network bandwidth in kilobits per second. |
mysql.queries_type | Breaks down queries by type (SELECT, DELETE, etc.). |
mysql.connections_active | Active database connections. |
Advanced MySQL Performance Monitoring Techniques
Netdata takes MySQL monitoring further with advanced techniques such as predictive analytics for query slowdowns and intricate analysis of I/O operations and buffer pool activities. This holistic approach empowers developers and DBAs to tune systems proactively and efficiently.
Diagnose Root Causes Or Performance Issues Using Key MySQL Statistics & Metrics
Netdata offers extensive MySQL metrics, including:
mysql.replication_lag: Monitors latency in replication processes.mysql.table_locks: Tracks the frequency and types of table locks.mysql.innodb_buffer_pool: Details about buffer pool usage and efficiency.
To explore these features firsthand or get started with sophisticated MySQL monitoring, sign up for a free trial or view Netdata live.
FAQs
What Is MySQL Monitoring?
MySQL monitoring involves tracking the performance and health of the MySQL database instances to ensure they run smoothly and efficiently.
Why Is MySQL Monitoring Important?
Effective monitoring helps detect and diagnose issues early, ensuring smooth database operations and optimal performance.
What Does a MySQL Monitor Do?
A MySQL monitor collects and visualizes metrics related to MySQL’s performance, helping you identify potential problems and optimize usage.
How Can I Monitor MySQL In Real Time?
You can monitor MySQL in real-time using Netdata, which provides real-time dashboards and comprehensive insights.