






NGINX VTS Monitoring
What Is NGINX VTS?
NGINX VTS (Virtual Traffic Status) is a third-party module for NGINX, a high-performance web server and reverse proxy. The VTS module provides detailed traffic status and metrics crucial for web server monitoring and management. It enables users to keep track of the overall health and performance of their NGINX server instances.
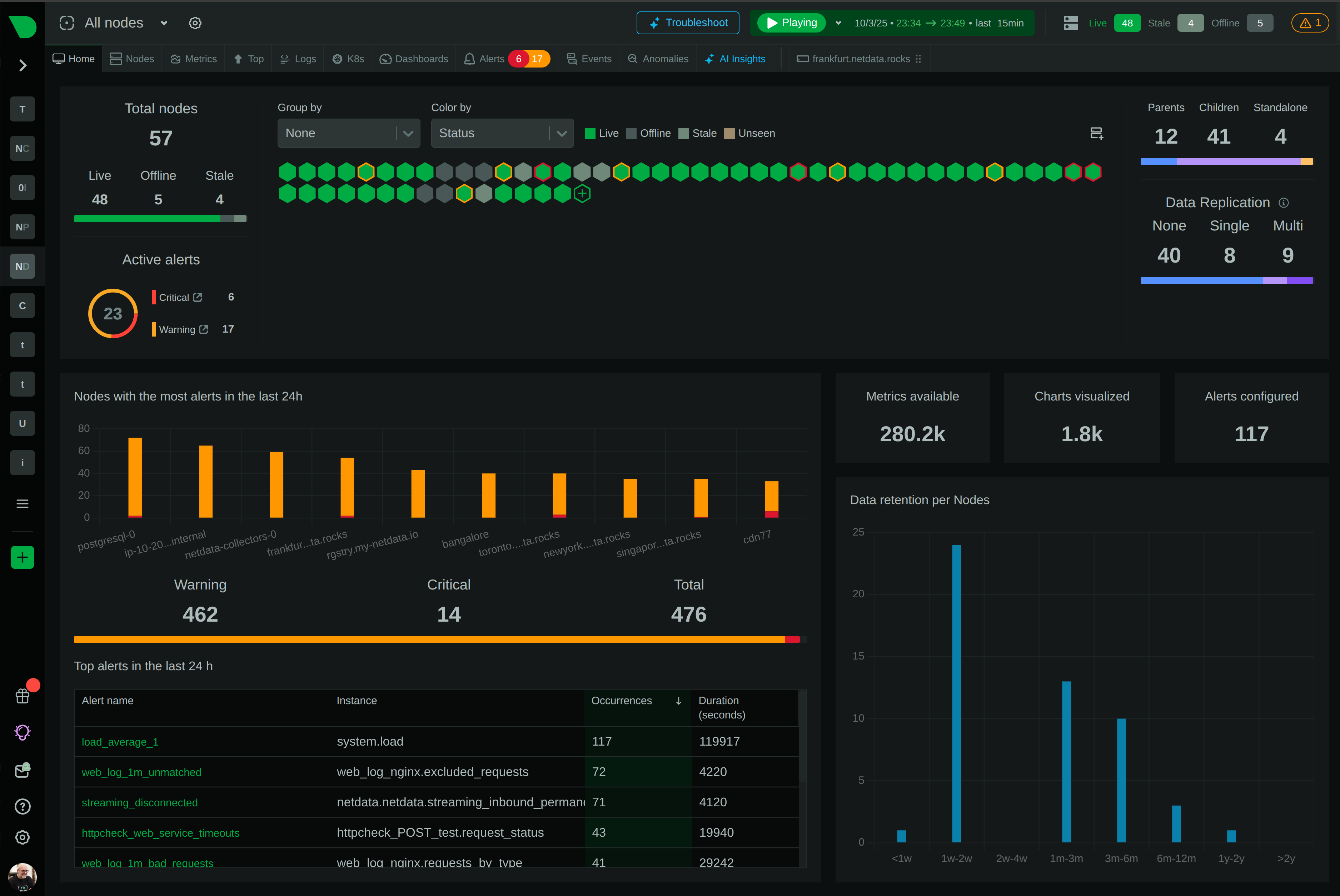
Monitoring NGINX VTS With Netdata
Using Netdata as an NGINX VTS monitoring tool allows you to collect and visualize vital metrics in real time, offering unprecedented visibility into your web server’s performance. With Netdata, you can monitor NGINX VTS effortlessly by leveraging its extensive integration capabilities and live data streaming features.
Why Is NGINX VTS Monitoring Important?
Monitoring NGINX VTS is essential as it ensures your web server is running optimally, facilitating quick detection and troubleshooting of any performance issues. It helps in identifying trends in traffic, understanding resource utilization, and maintaining an optimal configuration for peak performance.
What Are The Benefits Of Using NGINX VTS Monitoring Tools?
Advanced NGINX VTS monitoring tools, such as Netdata, provide a comprehensive view of your server’s operations. Key benefits include:
- Real-time monitoring: Instant visualization of metrics ensures timely responses to potential issues.
- Enhanced troubleshooting: Quickly pinpoint root causes using detailed metrics.
- Improved performance: Maintain optimal server configurations by observing trends and usage patterns.
Understanding NGINX VTS Performance Metrics
The NGINX VTS collector monitors several key metrics that are crucial for understanding web server performance:
nginxvts.requests_total
- Description: Total number of requests received by the server.
- Unit: requests/s
nginxvts.active_connections
- Description: Current active connections to the server.
- Unit: connections
nginxvts.connections_total
- Description: Total cumulative connections handled by the server.
- Unit: connections/s
nginxvts.uptime
- Description: Time duration the server has been running without restart.
- Unit: seconds
nginxvts.shm_usage
- Description: Usage of shared memory by NGINX.
- Unit: bytes
nginxvts.server_requests_total
- Description: Total client requests to the server.
- Unit: requests/s
nginxvts.server_responses_total
- Description: Total responses by HTTP code classes.
- Unit: responses/s
A full list of metrics and their descriptions can be found in the documentation.
Advanced NGINX VTS Performance Monitoring Techniques
Advanced monitoring involves setting up detailed alerting and anomaly detection mechanisms. With Netdata, you can leverage custom alarms to stay ahead of incidents. Furthermore, integrating with other Netdata plugins can provide a holistic view of your IT infrastructure.
Diagnose Root Causes Or Performance Issues Using Key NGINX VTS Statistics & Metrics
By monitoring key metrics, such as connection count and response codes, you can effectively diagnose performance issues. Utilizing tools for monitoring NGINX VTS, like Netdata, enables you to deep-dive into data patterns, diagnose anomalies, and address issues swiftly.
For an interactive experience, view Netdata live or sign up for a free trial to explore Netdata with your infrastructure.
FAQs
What Is NGINX VTS Monitoring?
NGINX VTS Monitoring refers to tracking and analyzing the performance metrics of NGINX using the Virtual Traffic Status module to optimize server performance.
Why Is NGINX VTS Monitoring Important?
It provides insights into server performance, enabling quick issue resolution, resource optimization, and maintaining server reliability.
What Does An NGINX VTS Monitor Do?
An NGINX VTS monitor collects and visualizes traffic metrics, server health, and performance data in real-time.
How Can I Monitor NGINX VTS In Real Time?
Using Netdata’s NGINX VTS monitoring tool, you can monitor metrics in real-time and diagnose issues effectively.