






NTPd Monitoring
What Is NTPd?
NTPd stands for Network Time Protocol daemon, an essential component for time synchronization across computer networks. By utilizing the NTP protocol, NTPd ensures that timekeeping is accurate and consistent across systems, which is crucial for numerous applications and services.
Monitoring NTPd With Netdata
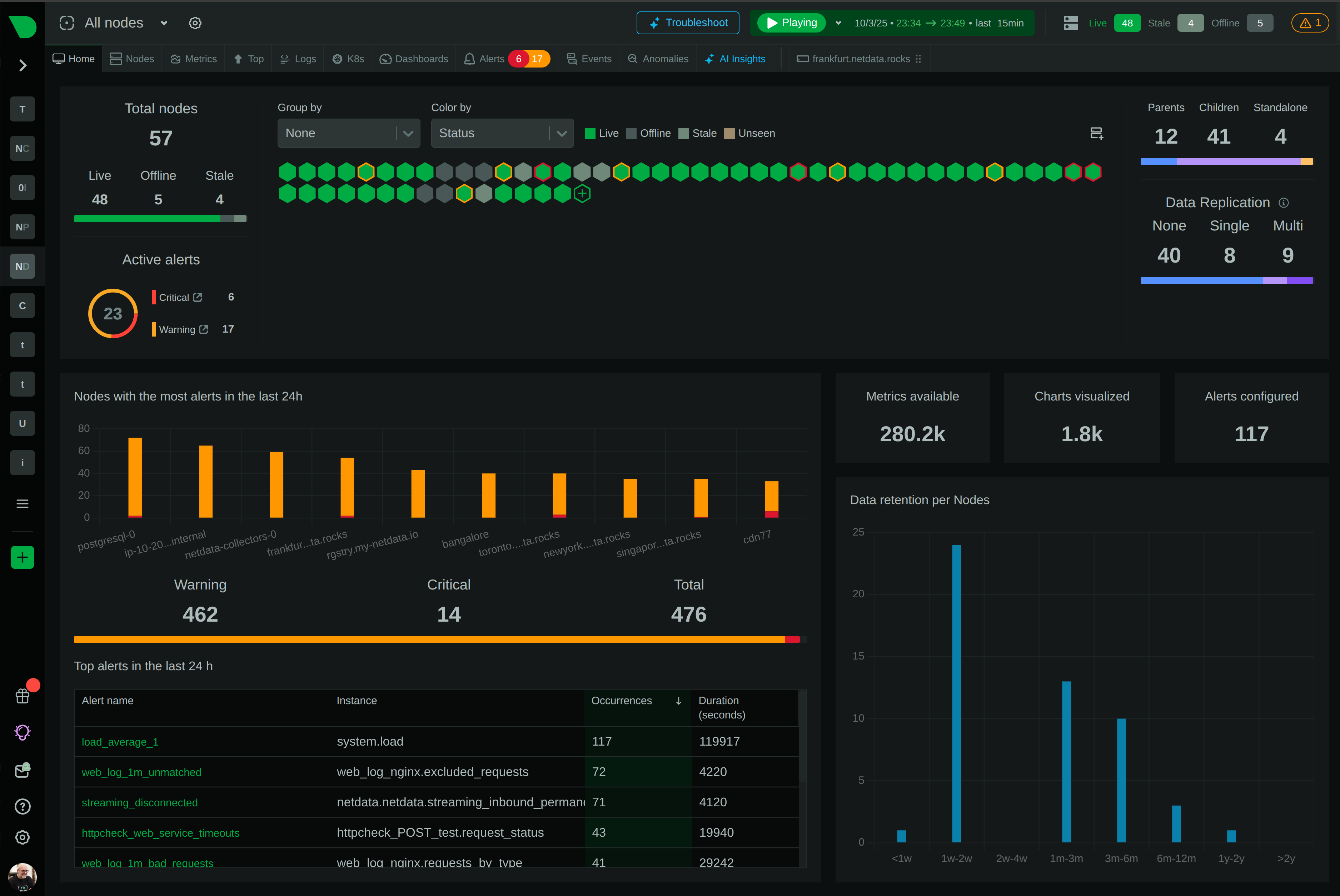
When you monitor NTPd with Netdata, you gain real-time insights into your time synchronization processes. The NTPd monitoring tool by Netdata offers comprehensive visibility into NTPd’s operational metrics, helping you to ensure your network’s timing accuracy.
Why Is NTPd Monitoring Important?
Monitoring NTPd is vital because accurate timekeeping is foundational for system logs, security protocols, and data integrity. Inconsistencies in time can lead to synchronization issues, impacting everything from file timestamps to scheduled tasks. Regular monitoring detects any deviations early, enabling quick resolutions.
What Are The Benefits Of Using NTPd Monitoring Tools?
Using tools for monitoring NTPd like Netdata, you receive efficient monitoring with minimal configuration. Netdata’s solution is lightweight, offers detailed metrics, and automatically adapts to changes, making it perfect for dynamic environments. Additionally, Netdata’s Live Demo showcases the tool’s capabilities in a live setup.
Understanding NTPd Performance Metrics
To effectively monitor NTPd, understanding its key performance metrics is fundamental. Metrics are categorized between global and peer-specific insights.
Global Metrics
- ntpd.sys_offset: Combined offset of server relative to the host in milliseconds.
- ntpd.sys_jitter: Combined system jitter, reflecting stability, measured in milliseconds.
- ntpd.sys_frequency: Frequency offset relative to hardware clock, measured in ppm (parts per million).
- ntpd.sys_wander: Clock frequency wander, also in ppm.
- ntpd.sys_rootdelay: Total roundtrip delay to the primary reference clock, measured in milliseconds.
- ntpd.sys_rootdisp: Total dispersion or deviation from the reference clock, measured in milliseconds.
- ntpd.sys_stratum: Indicates the stratum level; lower is preferred.
- ntpd.sys_tc: Time constant and poll exponent in log2.
- ntpd.sys_precision: Measurement precision in log2.
Peer Metrics
- ntpd.peer_offset: Peer offset in milliseconds.
- ntpd.peer_delay: Peer delay in milliseconds.
- ntpd.peer_dispersion: Peer dispersion in milliseconds.
- ntpd.peer_jitter: Peer jitter measuring stability, in milliseconds.
- ntpd.peer_xleave: Interleave delay of the peer in milliseconds.
- ntpd.peer_rootdelay: Roundtrip delay to the primary reference clock of the peer in milliseconds.
- ntpd.peer_rootdisp: Root dispersion to the primary reference clock of the peer in milliseconds.
- ntpd.peer_stratum: Peer stratum, denoting hierarchy.
- ntpd.peer_hmode, ntpd.peer_pmode: Host and peer mode.
- ntpd.peer_hpoll, ntpd.peer_ppoll: Host and peer poll exponent, in log2.
- ntpd.peer_precision: Peer precision in log2.
Advanced NTPd Performance Monitoring Techniques
For deeper insights into NTPd, leverage multi-instance monitoring to track both local and remote NTPd instances. Configurations can be adjusted to include peer metrics by setting collect_peers: yes in the configuration file, allowing for expanded visibility into the protocol’s operations and interactions.
Diagnose Root Causes Or Performance Issues Using Key NTPd Statistics & Metrics
Through the detailed statistics and metrics available with Netdata, diagnosing the root causes of synchronization problems becomes straightforward. Analyzing patterns from metrics like system jitter or peer delay can reveal network glitches or misconfigurations affecting time accuracy.
To experience these capabilities, consider exploring our Live Demo or signing up for a free trial.
FAQs
What Is NTPd Monitoring?
NTPd monitoring involves tracking the performance and synchronization accuracy of the Network Time Protocol daemon across systems.
Why Is NTPd Monitoring Important?
It ensures time consistency and integrity across systems, preventing errors in logging and scheduled operations.
What Does An NTPd Monitor Do?
An NTPd monitor tracks and reports on synchronization accuracy and highlights any deviations from expected performance.
How Can I Monitor NTPd In Real Time?
Netdata offers a powerful NTPd monitoring tool that provides real-time insights and analytics, enhancing your ability to maintain time accuracy across your network.